
Огляд відеокарт AMD Radeon RX 5700 і Radeon RX 5700 XT: нарешті вийшло!

Але тепер, вирішивши питання з центральними процесорами AMD набралася сил для атаки на ринок дискретних графічних карт. Сьогодні ми представляємо огляд прискорювачів Radeon RX 5700 і Radeon RX 5700 XT, з допомогою яких AMD має намір потіснити NVIDIA з ринкової ніші, яку окупували молодші моделі серії GeForce RTX — 2060 та 2070. Причому на цей раз головна ставка AMD зроблена не на передовій 7 нм техпроцес, по якому випускають чіп Navi, а на абсолютно нову логіку RDNA, яка прийшла на зміну GCN — архітектурі з без малого восьмирічним стажем. RDNA покликана вирішити проблеми, які завадили чіпам Polaris Vega і в повну силу виступити проти конкуруючого кремнію Pascal і Тьюрінга, а потім — якщо перший досвід буде вдалим — вона відкриє дорогу прискорювачів AMD до боротьби за титул абсолютного чемпіона.
Важко втриматися від аналогій з архітектурою Zen, якій вдалося за пару років перевернути ринок центральних процесорів, так і в історії ATi є приклади революційних перетворень. І все-таки, які обставини спонукали розробників Radeon 5000-ї серії відмовитися від перевіреної архітектурою GCN на користь іншого рішення і що такого в RDNA, щоб на ринку дискретних GPU знову виникла інтенсивна конкуренція? Спробуємо розібратися в цих питаннях, а потім приступимо до довгоочікуваним тестів Radeon RX 5700 і Radeon RX 5700 XT.
⇡#Нова архітектура RDNA
У перші роки GCN, яка дебютувала разом з прискорювачами Radeon HD 7970 ще в кінці 2011 року, графічні процесори AMD, за великим рахунком, зовсім не поступалися продуктів на чіпах NVIDIA Kepler з енергоефективності та швидкодії. Однак перехід до архітектури Maxwell, а потім Pascal, дозволив конкурентам AMD радикально збільшити продуктивність в 3D-рендерінгу, залишаючись у межах колишнього резерву потужності. GCN, тим не менш, завжди тримала паритет з чіпами NVIDIA по масиву обчислювальних блоків, однак колосальний резерв теоретичного швидкодії, яким відрізняються продукти AMD, цілком розкривається тільки в розрахунках загального призначення — не дивно, адже GCN і була задумана як рішення для завдань GP-GPU на противагу попереднього архітектурі TeraScale, орієнтованої переважно на ігри.
Для ринку дискретних відеокарт визначальне значення має показник швидкодії на рубль, а не на ват потужності, тому економний гаманець нерідко голосує саме за «червоних». Тим не менш, якщо чіпи GCN з певного моменту втратили можливість настільки ефективно транслювати терафлопсы розрахункової продуктивності в швидкодію 3D-додатків, для того, щоб підтримувати напруження боротьби, відеокарт Radeon потрібні більші чіпи, ніж ті, якими задовольняється NVIDIA. А в гонитві за локальними перемогами в тій чи іншій ціновій ніші AMD раз за разом примушувала GPU працювати на межі оптимальної зони тактових частот і напруги. В результаті AMD вже давно не претендує на корону абсолютного швидкодії, так і в нижніх категоріях продуктивності NVIDIA було легше надати відеокарті такі характеристики, щоб виправдати, як правило, більш високу роздрібну ціну.
Завдяки архітектурі Тьюринга NVIDIA зробила черговий стрибок в енергоефективності, і тепер стало абсолютно ясно, що далі AMD вже не може їхати по накатаних рейках. Крім того, архітектура GCN, незважаючи на постійні оптимізації і спроби консервативної переробки, які відбувалися в кожному новому поколінні кремнію, не володіє такими новаторськими функціями, як апаратне прискорення трасування променів і обробки даних методом машинного навчання. Проте AMD було не так-то просто відмовитися від спадщини GCN на користь абсолютно нової мікроархітектури. Свою роль зіграв і ймовірний дефіцит бюджету R&D в ті роки, коли компанія працювала чи не в збиток за плачевного стану справ на ринку центральних процесорів, і невдале партнерство з напівпровідниковим контрактором GlobalFoundries, який спершу анулював всі плани по запуску лінії 10 нм, а потім і зовсім припинив роботу над будь-якими новими вузлами після 14 нм FinFET.
Простір для маневру напевно обмежено і союзом з виробниками консолей, для яких AMD розробила цілу серію SoC з графічним ядром архітектури GCN. NVIDIA за всіма цими причин почуває себе більш вільно і не соромиться проводити різкі зміни в архітектурі GPU. Неспроста її то і справа звинувачують в тому, що сучасні ігри, розраховані на Direct3D 12 і Vulkan, з рук геть погано працюють на старих GPU архітектури Kepler і Maxwell — вся справа в тому, як сильно Pascal і Тьюрінга відрізняються від минулих ітерацій «зеленого» кремнію.
Однак для прискорювачів Radeon все-таки настав доленосний момент. Як стверджує AMD, над принципами архітектури RDNA компанія працювала протягом восьми років, і остання, на відміну від GCN, глибоко йде корінням в завдання GP-GPU, цілком сфокусована на швидкодії 3D-додатків. Це ще зовсім не означає, що RDNA не підходить для обчислень загального призначення, але місце в цій ніші і раніше буде зайнято існуючими і, напевно, прийдешніми продуктами на основі GCN. AMD пішла успішному наприклад NVIDIA і відтепер збирається підтримувати два окремих напрямки архітектури GPU — RDNA для ігрових прискорювачів і GCN для серверів і робочих станцій.
⇡#Легше і швидше: Compute Unit графічного процесора в GCN і RDNA
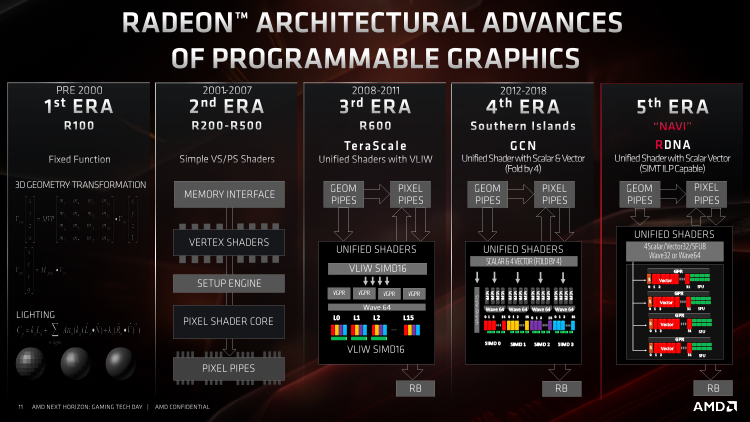
Для того, щоб зрозуміти фундаментальні відмінності між RDNA і GCN, спершу доведеться освіжити в пам'яті основні принципи масивно-паралельних обчислювальних, якими є GPU, і конкретику їх реалізації в чіпах AMD починаючи з Tahiti — самого першого кристала на основі GCN.
Левову частку кожного сучасного GPU займає масив шейдерних ALU. AMD називає їх потоковими процесорами, NVIDIA — ядрами CUDA, але в сутності і той, і інший блок виконує одну функцію — арифметичні операції над цілочисельними або речовими (з плаваючою точкою) даними. Але сила GPU полягає в тому, яким чином організована спільна робота шейдерних ALU. 3D-рендерінг і маса обчислювальних завдань іншого роду передбачає виконання однотипних дій над масивом різних операндів, тому обчислювальні блоки всередині чіпа групуються так, щоб одна інструкція могла зайняти в один і той же час кілька ALU, а дані надходять на обробку у вигляді кількох потоків (threads). Група з 32 потоків у термінології NVIDIA називається warp, GCN оперує групами по 64 потоку під назвою wavefront. Відповідно, кожна інструкція warp'a або wavefront'а дозволяє виконати необхідну операцію над 32 або 64 операндами (останні ми будемо далі називати робочими одиницями — work items).
Основним будівельним блоком архітектурою GCN є Compute Unit (CU) — саме його, а не окремі ALU, можна вважати аналогом ядра центральних процесорів, оскільки тільки CU цілком має здатність декодувати і відправляти інструкції на виконання.

Compute Unit містить 64 т.зв. векторних ALU, розділених на чотири блоки SIMD (Single Instruction Multiple Data). І хоча wavefront'и в архітектуру GCN складаються саме з 64 потоків, кожен SIMD обробляє власний wavefront паралельно з іншими SIMD'ами, а оскільки в кожному SIMD'е є всього лише 16 ALU, для виконання однієї інструкції йому необхідно чотири такту — це ключова риса архітектури GCN, визначає чимало сильних і слабких сторін даної архітектури. Інша важлива особливість полягає в тому, що векторний планувальник в CU всього один, і для того, щоб завантажити всі чотири SIMD роботою, вони отримують власні інструкції по черзі.
Для того, щоб запустити CU з нуля, потрібно витратити чотири такту, а протягом трьох перших частина ALU буде простоювати. Але у подібної логіки є й інший недолік. Вся справа в тому, що далеко не кожна інструкція вимагає повного завантаження 16-ти векторых ALU протягом чотирьох тактів. Wavefront'ам властиво гілкуватися, і в цей момент виходить так, що частина робочих одиниць включає одну операцію, а частина — іншу. SIMD повинен проходити «гілки» в два прийоми, незалежно від того, скільки векторних ALU при цьому буде діяти. Крім того, CU завжди вимагає не менше чотирьох wavefront'ів для максимального завантаження ALU — умова, що по тим або іншим причинам може короткочасно порушуватися.
Щоб знизити вплив цих факторів і адаптувати GPU до операцій з меншою кількістю потоків, творці архітектури RDNA здійснили перехід від 64-потокових до 32-потоковим wavefront'ам. CU тепер містить два SIMD'a 32 векторних ALU, і кожен SIMD забезпечений окремим планувальником. CU архітектури RDNA розрахований на виконання двох інструкцій протягом одного такту, в той час як CU чіпів GCN виконує чотири інструкції протягом чотирьох тактів.
Зауважимо, що оскільки wavefront'а в той же час став в два рази вже, стара і нова архітектури є еквівалентними за терафлопсам на один CU — ні про яке подвоєння пропускної спроможності тут мови не йде. Тим не менш, RDNA дійсно зобов'язана проявити високу ефективність у завданнях з «легкопоточной» навантаженням, і на цьому всі плюси реорганізації CU далеко не закінчуються. Так, завдяки окремим планувальникам необхідно обслуговуючим власні SIMD'и, і одночасної віддачі двох інструкцій кожен такт, RDNA характеризується зниженою латентністю виконання індивідуальних інструкцій. І нарешті, у RDNA є ще одне, не настільки очевидне, гідність. Як і в GCN, SIMD тут не прив'язаний до єдиного wavefront'в — кожен раз, коли планувальник дає інструкцію на виконання, вона може бути обрана з декількох wavefront'ів (аж до 10 на кожен SIMD в GCN 20 в RDNA). Але кількість потоків, які перебувають у робочому пулі окремо взятого CU, в результаті зменшилася з 2560 до 1280 — це означає, що в кешах тепер знаходяться менш різнорідні дані та їх обсяг використовується більш економно.
Тим не менш, темп виконання однієї інструкції в чотири такту, властивий GCN, був спочатку встановлений не без вагомих підстав. Поки інструкція «бігає» SIMD протягом чотирьох тактів, CU може дочекатися отримання даних, необхідних для наступної інструкції — наприклад, з оперативної пам'яті, звернення до якої відбувається цілу вічність за мірками внутрішньої логіки GPU. Архітектура RDNA, навпаки, пролетить через інструкції wavefront'а, поки не зіткнеться з необхідністю очікування даних. Звичайно, SIMD в цей момент може перейти на один з 19 інших wavefront'ів, але можливо і альтернативне рішення проблеми. RDNA допускає роботу зі старим, 64-потоковим форматом wavefront'а. В такому режимі інструкція широкого wavefront'а віддається на виконання в два прийоми, і в період відпрацювання за два такти латентність в очікуванні відсутніх даних ефективно маскуються.

Широкі і вузькі wavefront'и можуть співіснувати в межах робочого пулу одного SIMD без необхідності в зміні контексту, проте специфіку вибору між тим чи іншим форматом — чи існують в ISA архітектури RDNA інструменти, що визначають ширину wavefront'а чи це є рішенням драйвера AMD не розкриває. Як би те ні було, усталені програми GP-GPU, ретельно оптимізовані з розрахунком на особливості GCN, так само як і ігрові шейдери, скомпільовані в машинному коді (Shader Intrinsics), напевно потребують ревізії, щоб витягти з RDNA максимально високу ефективність.
⇡#Скалярні ALU у GCN і RDNA
Крім векторних SIMD, які обслуговує власний планувальник, в кожному Compute Unit'е графічних процесорів AMD — як GCN, так і RDNA — існує скалярний блок з окремим цілочисельним ALU і логікою, виконує декодування і віддачу інструкцій. Цей компонент відкриває інструкції wavefront'а альтернативний шлях виконання — на той випадок, коли всі з 32-х або 64-х робочих одиниць містять однорідні дані, і можна сміливо замінити їх єдиною операцій замість того, щоб робити одну і ту ж роботу кілька десятків разів поспіль. У коді шейдерних kernel'ів скалярний блок, здебільшого обслуговує операції умовного розгалуження або переходу.
У GCN скалярний блок може бути використаний протягом кожного такту, але тільки одночасно з тим з чотирьох SIMD, до якого підійшла черга єдиного векторного планувальника. У RDNA скалярних блоків два, а оскільки чотиритактних ротація SIMD'ів пішла в минуле, вони здатні приймати інструкцію на виконання кожен такт. Тим не менш, з документації AMD не цілком зрозуміло, чи може скалярний блок GCN і RDNA отримувати інструкцію паралельно векторної інструкції відповідного SIMD'а. Зрозуміло, тоді SIMD і скалярний блок, повинні взяти інструкції з різних wavefront'ів, адже ні GCN, ні RDNA не допускають суперскалярне виконання, при якому одночасно виконується дві послідовні інструкції з одного потоку. Або все навпаки, SIMD змушений поступитися свій такт прийому інструкції на користь скалярного блоку. Як би те ні було, непрямі ознаки вказують на те, що одночасна віддання і виконання скалярних і векторних інструкцій у рамках GCN і RDNA все-таки можлива, що додатково підсилює паралелізм в чіпах AMD.

⇡#Блоки спеціального призначення (SFU)
Третій тип виконавчих блоків, який присутній в Compute Unit'е GCN і RDNA, призначений для т. зв. операцій спеціального призначення. Під цим терміном ховаються тригонометричні функції, які нерідко використовуються при 3D-рендерінгу. В рамках GCN блок SFU являє собою окремий SIMD, що складається з чотирьох ALU, прив'язаний до кожного з основних векторних SIMD'ів, і служить в якості резервного шляху виконання інструкції wavefront'а — для цього потрібно 16 тактів, протягом яких векторний SIMD змушений діяти.
У RDNA використовується схожа організація SFU: з кожним з двох векторних SIMD асоційований SFU, в який входять 8 ALU. Таким чином, тригонометричні операції чіп RDNA теж виконує в темпі 1/4 від стандартних векторних інструкцій. Але є одна ключова відмінність: з загальних ресурсів векторый SIMD і SFU мають тільки порт планувальника, а в іншому оперують незалежно один від одного. Щоб CU міг завантажити SFU, векторний SIMD повинен пропустити лише один такт, а протягом трьох наступних, поки SFU відпрацьовує свою інструкцію, SIMD готовий приймати та виконувати інструкції в стандартному режимі. Ось ще одне джерело паралелізму і, в кінцевому рахунку, більш високою фактичної продуктивності в перерахунку на терафлопс, який сулжит графічним процесорам AMD архітектура RDNA.
⇡#Перероблена структура кешей
Як ми вже писали вище, виконання інструкцій з темпом в один такт, на який розрахована архітектура RDNA, робить її вразливою до затримок виконання, викликаним очікуванням даних, а значить чіп Navi особливо вимогливий до організації стека пам'яті — від внутрішніх кешей Compute Unit'а до інтерфейсу оперативної пам'яті. Адже навіть чіпи GCN, для яких характерна латентність виконання інструкції в чотири такту (включаючи «Вегу» з надзвичайно високою ПСП, яку забезпечує пам'ять HBM2) потребують доступу до даних на короткій відстані і значно виграють від розгону RAM. На щастя, творці RDNA не обійшли стороною цей момент і повністю змінили структуру кешей графічного процесора.
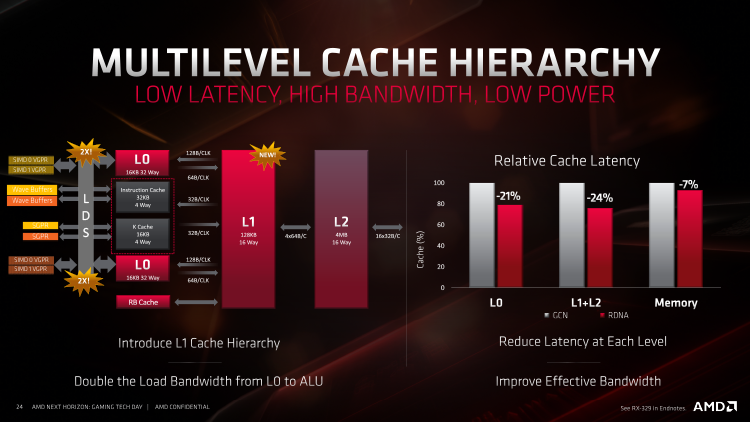
Окремі CU у складі GCN і RDNA згруповані по кілька штук і користуються декількома типами поділюваних ресурсів — таких, як 32-кілобайтний кеш інструкцій і скалярний кеш об'ємом до 16 Кбайт. Однак якщо в чіпах GCN ці сховища були спільними для чотирьох (а згодом трьох) CU, то в RDNA група пов'язаних CU, звана Workgroup Processor, зменшена до двох учасників, а конкуренція за ресурси в результаті слабшає. Навпаки, сховище LDS (Local Data Store), яке являє собою найбільш швидкий тип пам'яті після векторних регістрів SIMD, тепер теж стало загальним для двох CU, незважаючи на те, що обсяг LDS залишився незмінним (64 Кбайт). Втім, завдяки тому, що кількість потоків на окремо взятий CU при роботі з 32-потоковими wavefront'ами скоротилося вдвічі, це зміна також ні в якому разі не можна розглядати як крок назад порівняно з GCN.

Не менш грандіозні зміни відбулися на наступних рівнях стека пам'яті RDNA: 16-кілобайтний кеш L1 в межах окремо взятого CU тепер вважається кешем нульового рівня, а попутно інженери AMD збільшили його асоціативність з 4 до 32 каналів (а це, в свою чергу, значно впливає на відсоток попадань в кеш) і збільшили удвічі пропускну здатність дороги до векторних ALU. Місце старого L1 в ієрархії пам'яті RDNA тепер займає величезний 128-кілобайтний кеш, доступний десяти Compute Unit'ам, з 16-канальної асоціативністю. Він повинен зняти значну частину навантаження з кеша L2, адже останній обійшовся без значних змін після попередньої ітерації в чіпах Vega: при 16-канальної асоціативності і в обсязі 4 Мбайт кеш L2 чіпа Navi пов'язаний, з одного боку, з кожною секцією L1, а з іншого — за допомогою шини Infinity Fabric — з контролерами RAM і uncore-компонентами SoC (блоками DMA для комунікації між дискретними GPU, кодеком відеопотоку і т. д.).
І нарешті, на додаток до чергової оптимізації алгоритмів компресії кольору, RDNA допускає передачу стислих даних по тих ділянках конвеєра рендеринга, де в GCN було дозволено тільки рух «сирих» даних. Шейдерні програми можуть читати і записувати компресований колір не тільки в ПАМ'ЯТІ, але і кеш-пам'ять L1 і L2 (шейдерам в Polaris Vega і було дозволено тільки читання). Також можлива передача стисненого кольору з L2 в контролер дисплея.
⇡#Графічний процесор Navi 10
Найбільш розвиненою структурою в організації компонентів чіпа Navi є Shader Engine. У складі Navi 10 їх два — кожен містить по 20 CU і масив конвеєрів растеризації (ROP). Таким чином, повнофункціональна версія Navi 10 включає 2560 шейдерних ALU і 160 блоків фільтрації текстур. Серед минулого покоління чіпів можна безпомилково назвати аналог подібної конфігурації — це старший чіп сімейства Polaris. Тільки Polaris, незважаючи на дві ревізії після його дебюту у складі Radeon RX 480, таки не з'явився в комерційних пристроях з повністю активним набором обчислювальних блоків — у всіх відеокартах на його основі розблоковані лише 36 CU.
Однак між Polaris і Navi можна виявити істотні розходження, що виходять за межі внутрішньої організації Compute Unit'ів, яку ми обговорювали досі — починаючи з того, що Navi дісталося вдвічі більше ROP: 64 замість 32. Це абсолютно необхідна зміна back-end'a GPU в світлі того, що від RDNA очікується підвищена ефективність в 3D-рендерінгу — вважається, що Polaris уникав «бульбашок», що виникають при очікуванні відпрацювання ROP, просто за рахунок загального недоліку ефективної завантаження шейдерних ALU.
Вражаючий піксельний филлрейт, який розвивають 64 конвеєра растеризації, поєднується з підтримкою оперативної пам'яті типу GDDR6. Navi 10, як і старший Polaris, обходиться 256-бітною шиною ПАМ'ЯТІ, але висока пропускна здатність GDDR6 (14 Гбіт/с на контакт) гарантує необхідну більш ефективної архітектурі швидкість доступу до даних. Повна ревізія стека пам'яті, яку провели інженери AMD в чіпі Navi, закінчується підтримкою видалених комунікацій по шині PCI Express четвертого покоління. Втім, побачити PCI Express 4.0 у справі на перших порах дозволить тільки власна платформа AMD з процесорами Ryzen 3000-ї серії, а Navi 10 в будь-якому випадку не зможе завантажити настільки швидкий канал зв'язку з CPU.

Front-end чіпа представлений блоками обробки геометричних примітивів, причому AMD змінила конфігурацію ранніх стадій апаратного конвеєра таким чином, що частина геометричної логіки залишилася в межах Compute Engine (познайомтеся з ще одним терміном архітектури чіпів AMD) — структури, що об'єднує половину всього вмісту Shader Engine, — а загальний геометричний процесор, зайнятий відсіканням невидимих полігонів, винесений за її межі ближче до командних процесорам ACE (Asynchronous Compute Engine), распределяющим потоки шейдерних обчислень між Compute Unit'ами.
Всього Navi 10 може отримати аж до чотирьох геометричних примітивів, які пройшли стадію фільтрації невидимих поверхонь — як Vega. Однак нагадаємо, що в складі повністю функціонального чіпа Vega на 60 % більше шейдерних ALU і блоків фільтрації текстур, так що пропорція між потужністю геометричного front-end'a і основних ресурсів, що забезпечують текстурування і роботу шейдерних kernel'ів, в Наві явно більш вигідна.

Драйвер GPU автоматично включає тайловый рендеринг, що з'явився в графічних процесорах Vega, для того, щоб скоротити звернення до оперативної пам'яті і утримати дані, необхідні для растеризації і шейдерів, в межах кеша L2. А ось яким чином AMD надійшла з альтернативним конвеєром NGG (Next Generation Geometry), залишається загадкою. Vega обіцяла наростити пропускну здатність геометричного процесора з 4 до 17 примітивів за такт за умови, що код додатків навчиться використовувати т. н. примітивні шейдери (Primitive Shaders). Досі ця можливість не була використана на практиці — ні в ігрових движках, ні у вигляді розширень API так і не з'явилася підтримка Primitive Shaders через без малого два роки життя Vega на ринку ігрових прискорювачів.

Що стосується згаданих блоків ACE (Asynchronous Compute Engine), то і вони навчилися новим трюкам. У RDNA доступна така функція, як Asynchronous Compute Tunneling (ACT). Вона оперує на рівні черг інструкцій, які драйвер відеокарти отримує від графічного API — на відміну від preemption та інших методів, що працюють на рівні wavefront'ів і окремих ланцюжків даних для векторних ALU (наприклад, Direct3D 12 підтримує одну чергу для рендеринга і кілька для неграфічних розрахунків). Завдяки ACT графічний процесор здатний миттєво припинити прийом подальших інструкцій з черг, що мають нижчий пріоритет, заради того, щоб закінчити критично важливу роботу з іншої черги. Головною метою подібних оптимізацій, зрозуміло, є VR. Розробники «заліза» продовжують приділяти шоломів віртуальної реальності підвищену увагу, незважаючи на те, до якого жалюгідного стану сьогодні прийшла ця, колись перспективна ідея.
Однак всі ті нововведення, які увібрав у себе чіп Navi 10, не дісталися безкоштовно з точки зору компонентного бюджету. Старший Polaris при такій конфігурації основних обчислювальних блоків обходиться скромними 5,7 млрд транзисторів, а для того, щоб побудувати Navi 10, знадобилося вже 10,3 млрд — так багато місця займає додаткова керуюча логіка і набрякла система кешей. Не дивно, що AMD залишить архітектуру GCN для прискорювачів неграфічних розрахунків, адже всю цю площу можна просто забити шейдерними ALU, яким GCN завжди знайде роботу в GP-GPU.
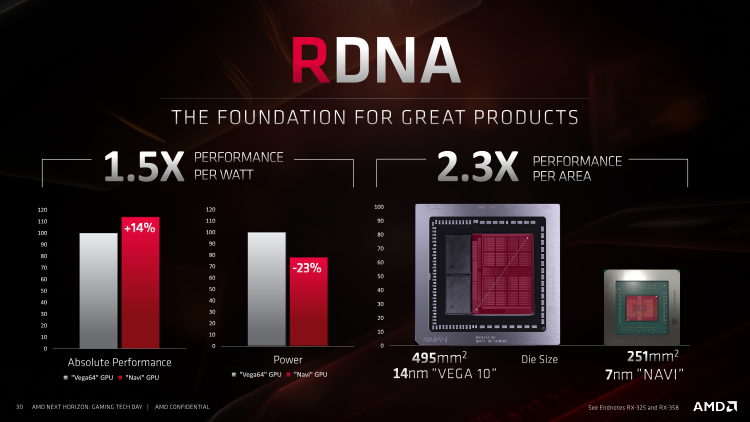
Для того, щоб ефективно задіяти ресурси чіпа в іграх, з такими жертвами волею-неволею доводиться миритися. Графічні процесори NVIDIA теж набирали вагу з кожним поколінням, адже масштаб змін в архітектурі RDNA можна порівняти одночасно з двома найбільшими переходами, які здійснив конкурент, — від Kepler до Maxwell і від Pascal до Тьюринга.
У всякому разі, техпроцес 7 нм дозволяє упаковувати додаткові транзистори набагато компактніше, ніж при нормі 14 нм. Площа Navi 10 становить 251 мм2 — трохи більше, ніж у Polaris 10/20, а щільність компонентів зросла на 67 %. Куди важливіше те, що в іграх Navi 10 обіцяє підвищити питоме швидкодія на площу чіпа в 2,3 рази порівняно з Vega 10, а швидкодія на ват — на 48 %. Примітно, що левову частку виграної потужності AMD відносить саме на рахунок архітектури RDNA, в той час як окремо взята зміна технологічної норми з 14 на 7 нм дала тільки 11 %. Чималий внесок в енергоефективність Navi внесла і схемотехніка кристала — в цій частині команда Radeon запозичила кращі методи у творців Ryzen.
Але тепер, вирішивши питання з центральними процесорами AMD набралася сил для атаки на ринок дискретних графічних карт. Сьогодні ми представляємо огляд прискорювачів Radeon RX 5700 і Radeon RX 5700 XT, з допомогою яких AMD має намір потіснити NVIDIA з ринкової ніші, яку окупували молодші моделі серії GeForce RTX — 2060 та 2070. Причому на цей раз головна ставка AMD зроблена не на передовій 7 нм техпроцес, по якому випускають чіп Navi, а на абсолютно нову логіку RDNA, яка прийшла на зміну GCN — архітектурі з без малого восьмирічним стажем. RDNA покликана вирішити проблеми, які завадили чіпам Polaris Vega і в повну силу виступити проти конкуруючого кремнію Pascal і Тьюрінга, а потім — якщо перший досвід буде вдалим — вона відкриє дорогу прискорювачів AMD до боротьби за титул абсолютного чемпіона.
Важко втриматися від аналогій з архітектурою Zen, якій вдалося за пару років перевернути ринок центральних процесорів, так і в історії ATi є приклади революційних перетворень. І все-таки, які обставини спонукали розробників Radeon 5000-ї серії відмовитися від перевіреної архітектурою GCN на користь іншого рішення і що такого в RDNA, щоб на ринку дискретних GPU знову виникла інтенсивна конкуренція? Спробуємо розібратися в цих питаннях, а потім приступимо до довгоочікуваним тестів Radeon RX 5700 і Radeon RX 5700 XT.
⇡#Нова архітектура RDNA
У перші роки GCN, яка дебютувала разом з прискорювачами Radeon HD 7970 ще в кінці 2011 року, графічні процесори AMD, за великим рахунком, зовсім не поступалися продуктів на чіпах NVIDIA Kepler з енергоефективності та швидкодії. Однак перехід до архітектури Maxwell, а потім Pascal, дозволив конкурентам AMD радикально збільшити продуктивність в 3D-рендерінгу, залишаючись у межах колишнього резерву потужності. GCN, тим не менш, завжди тримала паритет з чіпами NVIDIA по масиву обчислювальних блоків, однак колосальний резерв теоретичного швидкодії, яким відрізняються продукти AMD, цілком розкривається тільки в розрахунках загального призначення — не дивно, адже GCN і була задумана як рішення для завдань GP-GPU на противагу попереднього архітектурі TeraScale, орієнтованої переважно на ігри.
Для ринку дискретних відеокарт визначальне значення має показник швидкодії на рубль, а не на ват потужності, тому економний гаманець нерідко голосує саме за «червоних». Тим не менш, якщо чіпи GCN з певного моменту втратили можливість настільки ефективно транслювати терафлопсы розрахункової продуктивності в швидкодію 3D-додатків, для того, щоб підтримувати напруження боротьби, відеокарт Radeon потрібні більші чіпи, ніж ті, якими задовольняється NVIDIA. А в гонитві за локальними перемогами в тій чи іншій ціновій ніші AMD раз за разом примушувала GPU працювати на межі оптимальної зони тактових частот і напруги. В результаті AMD вже давно не претендує на корону абсолютного швидкодії, так і в нижніх категоріях продуктивності NVIDIA було легше надати відеокарті такі характеристики, щоб виправдати, як правило, більш високу роздрібну ціну.
Завдяки архітектурі Тьюринга NVIDIA зробила черговий стрибок в енергоефективності, і тепер стало абсолютно ясно, що далі AMD вже не може їхати по накатаних рейках. Крім того, архітектура GCN, незважаючи на постійні оптимізації і спроби консервативної переробки, які відбувалися в кожному новому поколінні кремнію, не володіє такими новаторськими функціями, як апаратне прискорення трасування променів і обробки даних методом машинного навчання. Проте AMD було не так-то просто відмовитися від спадщини GCN на користь абсолютно нової мікроархітектури. Свою роль зіграв і ймовірний дефіцит бюджету R&D в ті роки, коли компанія працювала чи не в збиток за плачевного стану справ на ринку центральних процесорів, і невдале партнерство з напівпровідниковим контрактором GlobalFoundries, який спершу анулював всі плани по запуску лінії 10 нм, а потім і зовсім припинив роботу над будь-якими новими вузлами після 14 нм FinFET.
Простір для маневру напевно обмежено і союзом з виробниками консолей, для яких AMD розробила цілу серію SoC з графічним ядром архітектури GCN. NVIDIA за всіма цими причин почуває себе більш вільно і не соромиться проводити різкі зміни в архітектурі GPU. Неспроста її то і справа звинувачують в тому, що сучасні ігри, розраховані на Direct3D 12 і Vulkan, з рук геть погано працюють на старих GPU архітектури Kepler і Maxwell — вся справа в тому, як сильно Pascal і Тьюрінга відрізняються від минулих ітерацій «зеленого» кремнію.
Однак для прискорювачів Radeon все-таки настав доленосний момент. Як стверджує AMD, над принципами архітектури RDNA компанія працювала протягом восьми років, і остання, на відміну від GCN, глибоко йде корінням в завдання GP-GPU, цілком сфокусована на швидкодії 3D-додатків. Це ще зовсім не означає, що RDNA не підходить для обчислень загального призначення, але місце в цій ніші і раніше буде зайнято існуючими і, напевно, прийдешніми продуктами на основі GCN. AMD пішла успішному наприклад NVIDIA і відтепер збирається підтримувати два окремих напрямки архітектури GPU — RDNA для ігрових прискорювачів і GCN для серверів і робочих станцій.
⇡#Легше і швидше: Compute Unit графічного процесора в GCN і RDNA
Для того, щоб зрозуміти фундаментальні відмінності між RDNA і GCN, спершу доведеться освіжити в пам'яті основні принципи масивно-паралельних обчислювальних, якими є GPU, і конкретику їх реалізації в чіпах AMD починаючи з Tahiti — самого першого кристала на основі GCN.
Левову частку кожного сучасного GPU займає масив шейдерних ALU. AMD називає їх потоковими процесорами, NVIDIA — ядрами CUDA, але в сутності і той, і інший блок виконує одну функцію — арифметичні операції над цілочисельними або речовими (з плаваючою точкою) даними. Але сила GPU полягає в тому, яким чином організована спільна робота шейдерних ALU. 3D-рендерінг і маса обчислювальних завдань іншого роду передбачає виконання однотипних дій над масивом різних операндів, тому обчислювальні блоки всередині чіпа групуються так, щоб одна інструкція могла зайняти в один і той же час кілька ALU, а дані надходять на обробку у вигляді кількох потоків (threads). Група з 32 потоків у термінології NVIDIA називається warp, GCN оперує групами по 64 потоку під назвою wavefront. Відповідно, кожна інструкція warp'a або wavefront'а дозволяє виконати необхідну операцію над 32 або 64 операндами (останні ми будемо далі називати робочими одиницями — work items).
Основним будівельним блоком архітектурою GCN є Compute Unit (CU) — саме його, а не окремі ALU, можна вважати аналогом ядра центральних процесорів, оскільки тільки CU цілком має здатність декодувати і відправляти інструкції на виконання.
Compute Unit містить 64 т.зв. векторних ALU, розділених на чотири блоки SIMD (Single Instruction Multiple Data). І хоча wavefront'и в архітектуру GCN складаються саме з 64 потоків, кожен SIMD обробляє власний wavefront паралельно з іншими SIMD'ами, а оскільки в кожному SIMD'е є всього лише 16 ALU, для виконання однієї інструкції йому необхідно чотири такту — це ключова риса архітектури GCN, визначає чимало сильних і слабких сторін даної архітектури. Інша важлива особливість полягає в тому, що векторний планувальник в CU всього один, і для того, щоб завантажити всі чотири SIMD роботою, вони отримують власні інструкції по черзі.
Для того, щоб запустити CU з нуля, потрібно витратити чотири такту, а протягом трьох перших частина ALU буде простоювати. Але у подібної логіки є й інший недолік. Вся справа в тому, що далеко не кожна інструкція вимагає повного завантаження 16-ти векторых ALU протягом чотирьох тактів. Wavefront'ам властиво гілкуватися, і в цей момент виходить так, що частина робочих одиниць включає одну операцію, а частина — іншу. SIMD повинен проходити «гілки» в два прийоми, незалежно від того, скільки векторних ALU при цьому буде діяти. Крім того, CU завжди вимагає не менше чотирьох wavefront'ів для максимального завантаження ALU — умова, що по тим або іншим причинам може короткочасно порушуватися.
Щоб знизити вплив цих факторів і адаптувати GPU до операцій з меншою кількістю потоків, творці архітектури RDNA здійснили перехід від 64-потокових до 32-потоковим wavefront'ам. CU тепер містить два SIMD'a 32 векторних ALU, і кожен SIMD забезпечений окремим планувальником. CU архітектури RDNA розрахований на виконання двох інструкцій протягом одного такту, в той час як CU чіпів GCN виконує чотири інструкції протягом чотирьох тактів.
Зауважимо, що оскільки wavefront'а в той же час став в два рази вже, стара і нова архітектури є еквівалентними за терафлопсам на один CU — ні про яке подвоєння пропускної спроможності тут мови не йде. Тим не менш, RDNA дійсно зобов'язана проявити високу ефективність у завданнях з «легкопоточной» навантаженням, і на цьому всі плюси реорганізації CU далеко не закінчуються. Так, завдяки окремим планувальникам необхідно обслуговуючим власні SIMD'и, і одночасної віддачі двох інструкцій кожен такт, RDNA характеризується зниженою латентністю виконання індивідуальних інструкцій. І нарешті, у RDNA є ще одне, не настільки очевидне, гідність. Як і в GCN, SIMD тут не прив'язаний до єдиного wavefront'в — кожен раз, коли планувальник дає інструкцію на виконання, вона може бути обрана з декількох wavefront'ів (аж до 10 на кожен SIMD в GCN 20 в RDNA). Але кількість потоків, які перебувають у робочому пулі окремо взятого CU, в результаті зменшилася з 2560 до 1280 — це означає, що в кешах тепер знаходяться менш різнорідні дані та їх обсяг використовується більш економно.
Тим не менш, темп виконання однієї інструкції в чотири такту, властивий GCN, був спочатку встановлений не без вагомих підстав. Поки інструкція «бігає» SIMD протягом чотирьох тактів, CU може дочекатися отримання даних, необхідних для наступної інструкції — наприклад, з оперативної пам'яті, звернення до якої відбувається цілу вічність за мірками внутрішньої логіки GPU. Архітектура RDNA, навпаки, пролетить через інструкції wavefront'а, поки не зіткнеться з необхідністю очікування даних. Звичайно, SIMD в цей момент може перейти на один з 19 інших wavefront'ів, але можливо і альтернативне рішення проблеми. RDNA допускає роботу зі старим, 64-потоковим форматом wavefront'а. В такому режимі інструкція широкого wavefront'а віддається на виконання в два прийоми, і в період відпрацювання за два такти латентність в очікуванні відсутніх даних ефективно маскуються.
Широкі і вузькі wavefront'и можуть співіснувати в межах робочого пулу одного SIMD без необхідності в зміні контексту, проте специфіку вибору між тим чи іншим форматом — чи існують в ISA архітектури RDNA інструменти, що визначають ширину wavefront'а чи це є рішенням драйвера AMD не розкриває. Як би те ні було, усталені програми GP-GPU, ретельно оптимізовані з розрахунком на особливості GCN, так само як і ігрові шейдери, скомпільовані в машинному коді (Shader Intrinsics), напевно потребують ревізії, щоб витягти з RDNA максимально високу ефективність.
⇡#Скалярні ALU у GCN і RDNA
Крім векторних SIMD, які обслуговує власний планувальник, в кожному Compute Unit'е графічних процесорів AMD — як GCN, так і RDNA — існує скалярний блок з окремим цілочисельним ALU і логікою, виконує декодування і віддачу інструкцій. Цей компонент відкриває інструкції wavefront'а альтернативний шлях виконання — на той випадок, коли всі з 32-х або 64-х робочих одиниць містять однорідні дані, і можна сміливо замінити їх єдиною операцій замість того, щоб робити одну і ту ж роботу кілька десятків разів поспіль. У коді шейдерних kernel'ів скалярний блок, здебільшого обслуговує операції умовного розгалуження або переходу.
У GCN скалярний блок може бути використаний протягом кожного такту, але тільки одночасно з тим з чотирьох SIMD, до якого підійшла черга єдиного векторного планувальника. У RDNA скалярних блоків два, а оскільки чотиритактних ротація SIMD'ів пішла в минуле, вони здатні приймати інструкцію на виконання кожен такт. Тим не менш, з документації AMD не цілком зрозуміло, чи може скалярний блок GCN і RDNA отримувати інструкцію паралельно векторної інструкції відповідного SIMD'а. Зрозуміло, тоді SIMD і скалярний блок, повинні взяти інструкції з різних wavefront'ів, адже ні GCN, ні RDNA не допускають суперскалярне виконання, при якому одночасно виконується дві послідовні інструкції з одного потоку. Або все навпаки, SIMD змушений поступитися свій такт прийому інструкції на користь скалярного блоку. Як би те ні було, непрямі ознаки вказують на те, що одночасна віддання і виконання скалярних і векторних інструкцій у рамках GCN і RDNA все-таки можлива, що додатково підсилює паралелізм в чіпах AMD.
⇡#Блоки спеціального призначення (SFU)
Третій тип виконавчих блоків, який присутній в Compute Unit'е GCN і RDNA, призначений для т. зв. операцій спеціального призначення. Під цим терміном ховаються тригонометричні функції, які нерідко використовуються при 3D-рендерінгу. В рамках GCN блок SFU являє собою окремий SIMD, що складається з чотирьох ALU, прив'язаний до кожного з основних векторних SIMD'ів, і служить в якості резервного шляху виконання інструкції wavefront'а — для цього потрібно 16 тактів, протягом яких векторний SIMD змушений діяти.
У RDNA використовується схожа організація SFU: з кожним з двох векторних SIMD асоційований SFU, в який входять 8 ALU. Таким чином, тригонометричні операції чіп RDNA теж виконує в темпі 1/4 від стандартних векторних інструкцій. Але є одна ключова відмінність: з загальних ресурсів векторый SIMD і SFU мають тільки порт планувальника, а в іншому оперують незалежно один від одного. Щоб CU міг завантажити SFU, векторний SIMD повинен пропустити лише один такт, а протягом трьох наступних, поки SFU відпрацьовує свою інструкцію, SIMD готовий приймати та виконувати інструкції в стандартному режимі. Ось ще одне джерело паралелізму і, в кінцевому рахунку, більш високою фактичної продуктивності в перерахунку на терафлопс, який сулжит графічним процесорам AMD архітектура RDNA.
⇡#Перероблена структура кешей
Як ми вже писали вище, виконання інструкцій з темпом в один такт, на який розрахована архітектура RDNA, робить її вразливою до затримок виконання, викликаним очікуванням даних, а значить чіп Navi особливо вимогливий до організації стека пам'яті — від внутрішніх кешей Compute Unit'а до інтерфейсу оперативної пам'яті. Адже навіть чіпи GCN, для яких характерна латентність виконання інструкції в чотири такту (включаючи «Вегу» з надзвичайно високою ПСП, яку забезпечує пам'ять HBM2) потребують доступу до даних на короткій відстані і значно виграють від розгону RAM. На щастя, творці RDNA не обійшли стороною цей момент і повністю змінили структуру кешей графічного процесора.
Окремі CU у складі GCN і RDNA згруповані по кілька штук і користуються декількома типами поділюваних ресурсів — таких, як 32-кілобайтний кеш інструкцій і скалярний кеш об'ємом до 16 Кбайт. Однак якщо в чіпах GCN ці сховища були спільними для чотирьох (а згодом трьох) CU, то в RDNA група пов'язаних CU, звана Workgroup Processor, зменшена до двох учасників, а конкуренція за ресурси в результаті слабшає. Навпаки, сховище LDS (Local Data Store), яке являє собою найбільш швидкий тип пам'яті після векторних регістрів SIMD, тепер теж стало загальним для двох CU, незважаючи на те, що обсяг LDS залишився незмінним (64 Кбайт). Втім, завдяки тому, що кількість потоків на окремо взятий CU при роботі з 32-потоковими wavefront'ами скоротилося вдвічі, це зміна також ні в якому разі не можна розглядати як крок назад порівняно з GCN.
Не менш грандіозні зміни відбулися на наступних рівнях стека пам'яті RDNA: 16-кілобайтний кеш L1 в межах окремо взятого CU тепер вважається кешем нульового рівня, а попутно інженери AMD збільшили його асоціативність з 4 до 32 каналів (а це, в свою чергу, значно впливає на відсоток попадань в кеш) і збільшили удвічі пропускну здатність дороги до векторних ALU. Місце старого L1 в ієрархії пам'яті RDNA тепер займає величезний 128-кілобайтний кеш, доступний десяти Compute Unit'ам, з 16-канальної асоціативністю. Він повинен зняти значну частину навантаження з кеша L2, адже останній обійшовся без значних змін після попередньої ітерації в чіпах Vega: при 16-канальної асоціативності і в обсязі 4 Мбайт кеш L2 чіпа Navi пов'язаний, з одного боку, з кожною секцією L1, а з іншого — за допомогою шини Infinity Fabric — з контролерами RAM і uncore-компонентами SoC (блоками DMA для комунікації між дискретними GPU, кодеком відеопотоку і т. д.).
І нарешті, на додаток до чергової оптимізації алгоритмів компресії кольору, RDNA допускає передачу стислих даних по тих ділянках конвеєра рендеринга, де в GCN було дозволено тільки рух «сирих» даних. Шейдерні програми можуть читати і записувати компресований колір не тільки в ПАМ'ЯТІ, але і кеш-пам'ять L1 і L2 (шейдерам в Polaris Vega і було дозволено тільки читання). Також можлива передача стисненого кольору з L2 в контролер дисплея.
⇡#Графічний процесор Navi 10
Найбільш розвиненою структурою в організації компонентів чіпа Navi є Shader Engine. У складі Navi 10 їх два — кожен містить по 20 CU і масив конвеєрів растеризації (ROP). Таким чином, повнофункціональна версія Navi 10 включає 2560 шейдерних ALU і 160 блоків фільтрації текстур. Серед минулого покоління чіпів можна безпомилково назвати аналог подібної конфігурації — це старший чіп сімейства Polaris. Тільки Polaris, незважаючи на дві ревізії після його дебюту у складі Radeon RX 480, таки не з'явився в комерційних пристроях з повністю активним набором обчислювальних блоків — у всіх відеокартах на його основі розблоковані лише 36 CU.
Однак між Polaris і Navi можна виявити істотні розходження, що виходять за межі внутрішньої організації Compute Unit'ів, яку ми обговорювали досі — починаючи з того, що Navi дісталося вдвічі більше ROP: 64 замість 32. Це абсолютно необхідна зміна back-end'a GPU в світлі того, що від RDNA очікується підвищена ефективність в 3D-рендерінгу — вважається, що Polaris уникав «бульбашок», що виникають при очікуванні відпрацювання ROP, просто за рахунок загального недоліку ефективної завантаження шейдерних ALU.
Вражаючий піксельний филлрейт, який розвивають 64 конвеєра растеризації, поєднується з підтримкою оперативної пам'яті типу GDDR6. Navi 10, як і старший Polaris, обходиться 256-бітною шиною ПАМ'ЯТІ, але висока пропускна здатність GDDR6 (14 Гбіт/с на контакт) гарантує необхідну більш ефективної архітектурі швидкість доступу до даних. Повна ревізія стека пам'яті, яку провели інженери AMD в чіпі Navi, закінчується підтримкою видалених комунікацій по шині PCI Express четвертого покоління. Втім, побачити PCI Express 4.0 у справі на перших порах дозволить тільки власна платформа AMD з процесорами Ryzen 3000-ї серії, а Navi 10 в будь-якому випадку не зможе завантажити настільки швидкий канал зв'язку з CPU.
Front-end чіпа представлений блоками обробки геометричних примітивів, причому AMD змінила конфігурацію ранніх стадій апаратного конвеєра таким чином, що частина геометричної логіки залишилася в межах Compute Engine (познайомтеся з ще одним терміном архітектури чіпів AMD) — структури, що об'єднує половину всього вмісту Shader Engine, — а загальний геометричний процесор, зайнятий відсіканням невидимих полігонів, винесений за її межі ближче до командних процесорам ACE (Asynchronous Compute Engine), распределяющим потоки шейдерних обчислень між Compute Unit'ами.
Всього Navi 10 може отримати аж до чотирьох геометричних примітивів, які пройшли стадію фільтрації невидимих поверхонь — як Vega. Однак нагадаємо, що в складі повністю функціонального чіпа Vega на 60 % більше шейдерних ALU і блоків фільтрації текстур, так що пропорція між потужністю геометричного front-end'a і основних ресурсів, що забезпечують текстурування і роботу шейдерних kernel'ів, в Наві явно більш вигідна.
Драйвер GPU автоматично включає тайловый рендеринг, що з'явився в графічних процесорах Vega, для того, щоб скоротити звернення до оперативної пам'яті і утримати дані, необхідні для растеризації і шейдерів, в межах кеша L2. А ось яким чином AMD надійшла з альтернативним конвеєром NGG (Next Generation Geometry), залишається загадкою. Vega обіцяла наростити пропускну здатність геометричного процесора з 4 до 17 примітивів за такт за умови, що код додатків навчиться використовувати т. н. примітивні шейдери (Primitive Shaders). Досі ця можливість не була використана на практиці — ні в ігрових движках, ні у вигляді розширень API так і не з'явилася підтримка Primitive Shaders через без малого два роки життя Vega на ринку ігрових прискорювачів.
Що стосується згаданих блоків ACE (Asynchronous Compute Engine), то і вони навчилися новим трюкам. У RDNA доступна така функція, як Asynchronous Compute Tunneling (ACT). Вона оперує на рівні черг інструкцій, які драйвер відеокарти отримує від графічного API — на відміну від preemption та інших методів, що працюють на рівні wavefront'ів і окремих ланцюжків даних для векторних ALU (наприклад, Direct3D 12 підтримує одну чергу для рендеринга і кілька для неграфічних розрахунків). Завдяки ACT графічний процесор здатний миттєво припинити прийом подальших інструкцій з черг, що мають нижчий пріоритет, заради того, щоб закінчити критично важливу роботу з іншої черги. Головною метою подібних оптимізацій, зрозуміло, є VR. Розробники «заліза» продовжують приділяти шоломів віртуальної реальності підвищену увагу, незважаючи на те, до якого жалюгідного стану сьогодні прийшла ця, колись перспективна ідея.
Однак всі ті нововведення, які увібрав у себе чіп Navi 10, не дісталися безкоштовно з точки зору компонентного бюджету. Старший Polaris при такій конфігурації основних обчислювальних блоків обходиться скромними 5,7 млрд транзисторів, а для того, щоб побудувати Navi 10, знадобилося вже 10,3 млрд — так багато місця займає додаткова керуюча логіка і набрякла система кешей. Не дивно, що AMD залишить архітектуру GCN для прискорювачів неграфічних розрахунків, адже всю цю площу можна просто забити шейдерними ALU, яким GCN завжди знайде роботу в GP-GPU.
Для того, щоб ефективно задіяти ресурси чіпа в іграх, з такими жертвами волею-неволею доводиться миритися. Графічні процесори NVIDIA теж набирали вагу з кожним поколінням, адже масштаб змін в архітектурі RDNA можна порівняти одночасно з двома найбільшими переходами, які здійснив конкурент, — від Kepler до Maxwell і від Pascal до Тьюринга.
У всякому разі, техпроцес 7 нм дозволяє упаковувати додаткові транзистори набагато компактніше, ніж при нормі 14 нм. Площа Navi 10 становить 251 мм2 — трохи більше, ніж у Polaris 10/20, а щільність компонентів зросла на 67 %. Куди важливіше те, що в іграх Navi 10 обіцяє підвищити питоме швидкодія на площу чіпа в 2,3 рази порівняно з Vega 10, а швидкодія на ват — на 48 %. Примітно, що левову частку виграної потужності AMD відносить саме на рахунок архітектури RDNA, в той час як окремо взята зміна технологічної норми з 14 на 7 нм дала тільки 11 %. Чималий внесок в енергоефективність Navi внесла і схемотехніка кристала — в цій частині команда Radeon запозичила кращі методи у соз

 Значущість материнської плати: основа стабільної роботи вашого комп'ютераМатеринська плата є основою стабільної роботи комп'ютера, забезпечуючи зв'язок між усіма важливими компонентами. У цьому матеріалі ми розглянемо, чому материнська плата така важлива, як вона впливає на продуктивність та стабільність системи, а також як правильно вибрати плату для вашого комп'ютера.
Значущість материнської плати: основа стабільної роботи вашого комп'ютераМатеринська плата є основою стабільної роботи комп'ютера, забезпечуючи зв'язок між усіма важливими компонентами. У цьому матеріалі ми розглянемо, чому материнська плата така важлива, як вона впливає на продуктивність та стабільність системи, а також як правильно вибрати плату для вашого комп'ютера. Для чого в комп'ютері потрібен процесор?Що таке процесор і навіщо він потрібен у комп’ютері? Дізнайтесь, яку роль відіграє процесор у роботі комп’ютера, від чого залежить його швидкодія та як він впливає на продуктивність системи.
Для чого в комп'ютері потрібен процесор?Що таке процесор і навіщо він потрібен у комп’ютері? Дізнайтесь, яку роль відіграє процесор у роботі комп’ютера, від чого залежить його швидкодія та як він впливає на продуктивність системи.